DWH, part 3: SQL Code Generator
by Dmytro Lytvyn
As we found out in the previous article, to properly populate each table in the DWH, while checking for duplicates, storing changes history etc., we have to write a lot of SQL code. Fortunately, this code will mostly be the same, and therefore we can automate this with some kind of code generator. Of course, each table has a different primary (business) key and foreign keys, which will reference other tables. Additionally, if the required key records are missing in those foreign tables, we would like to create so-called inferred records in those referenced tables.
So we need some kind of configuration for each of the tables we want to generate ETL code for. We can, of course, prepare such configs in some text files, and run the code generator from a command line, but that would not be very user-friendly. Also, it would be nice to be able to have a UI to just select a staging table from a list, allow the tool to obtain the list of columns from it automatically, and then select the business key and foreign key columns by just clicking on them. And since we’re obviously not going to write the configuration by hand, it would make sense to store it in a single location, for example SQLite database file.
My “weapon of choice” for the code generator is Python, and after trying out several cross-platform UI libraries, I ended up choosing WxWidgets. The resulting tool is open-source, you can find the Git repository here: https://github.com/dmytro-lytvyn/dwh-sql-codegen. The code itself is very hacky and not really reusable, because as soon as it started to work, it has already fulfilled its purpose, and since it’s only used once for every table we need to import, I can tolerate some small UI-related bugs. Ideally, it would be nice to separate the UI from the code generation completely, and also move out SQL code snippets into a separate configurable template storage, but I have more interesting things to work on in my spare time :) But if you’re interested, please feel free to contribute.
You can find a tutorial on how to use the Code Generator in the README of the repository. But if we look at the process from the start, the typical use-case scenario to import a new table into DWH is the following:
- Create and run a DDL for a staging table with the same structure as the original in a source database (usually just by copying the table DDL from pgAdmin), but without any indexes. Staging table DDL:
drop table if exists stage.customer;
create table stage.customer
(
order_id bigint,
date_created timestamp,
date_updated timestamp,
email varchar(255),
first_name varchar(255),
last_name varchar(255),
is_enabled boolean,
additional_data json,
version integer
);
grant select on stage.customer to read_stage;
grant all on stage.customer to write_stage;
- Prepare the SQL to truncate the staging table and load into it either the last several days of changes, or the full source table (depending on a parameter substituted before the script execution by the ETL processes). The first load will obviously be a full load. Note that we specify the exact list of columns when selecting from a source table. This makes sure the ETL doesn’t fail when a column is added. We can always add missing new columns later and reload the data. Staging table Load script:
select stage.dblink_connect('product','host=#PSQL_PRODUCT_SERVER# port=#PSQL_PRODUCT_PORT# dbname=#PSQL_PRODUCT_DB# user=#PSQL_PRODUCT_LOGIN# password=#PSQL_PRODUCT_PASS#');
truncate table stage.customer;
insert into stage.customer
select *
from stage.dblink(
'product',
'
select
order_id,
date_created,
date_updated,
email,
first_name,
last_name,
is_enabled,
additional_data,
version
from prod.customer
where (date_updated >= ''#YESTERDAY3_Y-M-D#''
or ''#FULL_LOAD#'' = ''1''
)
'
)
as t1 (
order_id bigint,
date_created timestamp,
date_updated timestamp,
email varchar(255),
first_name varchar(255),
last_name varchar(255),
is_enabled boolean,
additional_data json,
version integer
);
select stage.dblink_disconnect('product');
-
Run the SQL Code Generator, add a Project and Stage Db, select and import the new staging table into a specific project in it.

-
Rename the target table, specify the target database schema and some other parameters on table level, like whether we need to check for changed our deleted records or whether we need to store the changes history. Of course, to check for deleted records, you will need to fully load the staging table from the source every time!

-
Check the list of columns and adapt the column types where necessary. It’s also possible to change the existing or add new columns with custom SQL expressions.
-
Select one or more columns making up the business key.
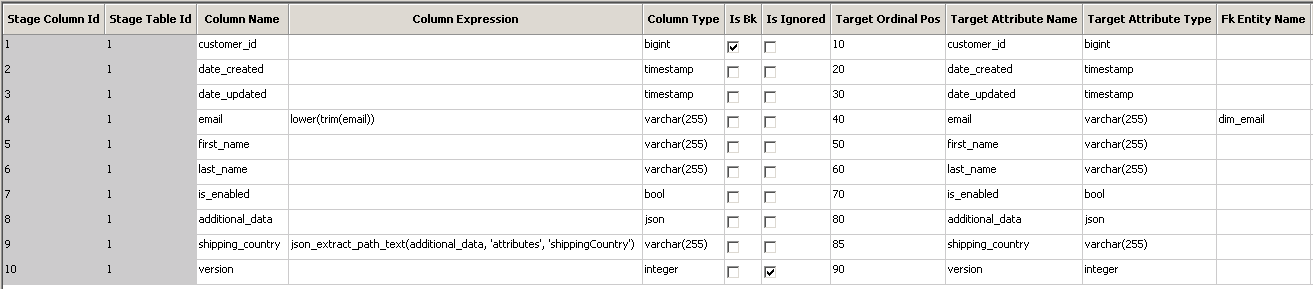
-
For each foreign key, select the target table and some additional parameters like whether we want to create inferred records if the target record is missing, the column name to be populated with the known value for such cases, whether this column can be used as a “date_updated” column, whether this column should be indexed etc.

-
Generate the DDL code for the target tables with Ctrl+D (Command+D on Mac), and generate the ETL SQL code with Ctrl+G (Command+G). The Code Generator will offer to save them as files named after the target table.
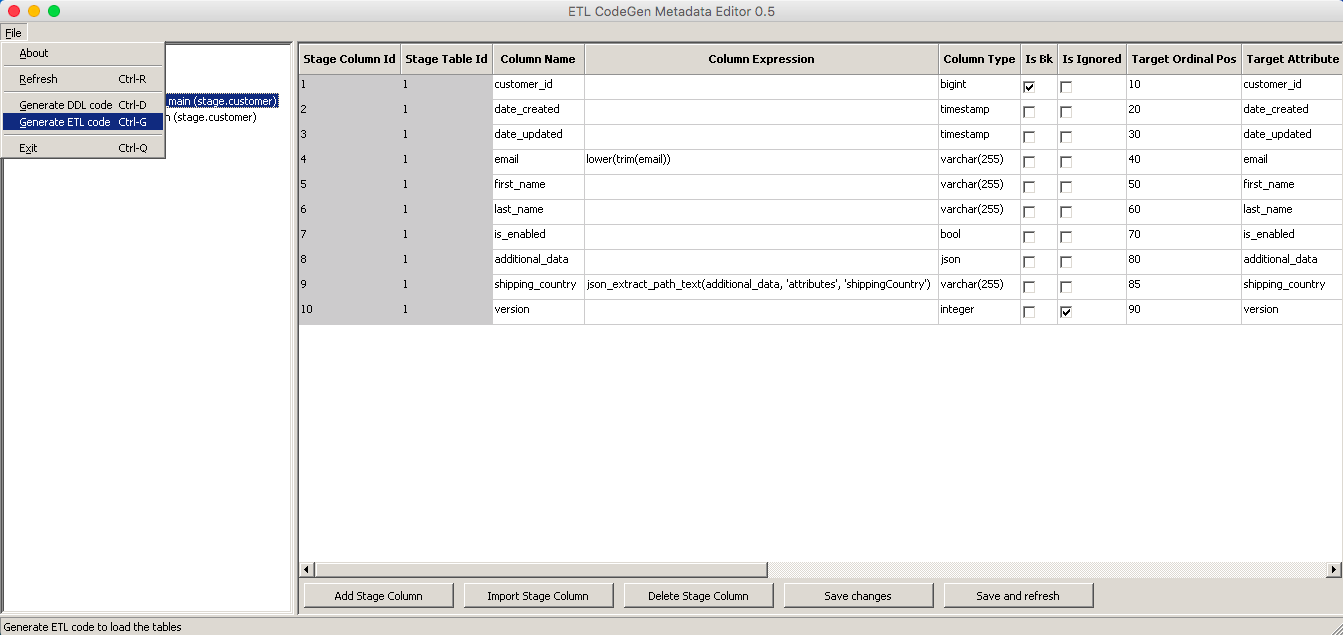 Here is what the end results might look like.
Target table DDL script:
Here is what the end results might look like.
Target table DDL script:
-- Generating DDL for all required tables, only run if the tables don't exist yet
drop table if exists dw.dim_customer_pk_lookup;
drop sequence if exists dw.dim_customer_seq;
create sequence dw.dim_customer_seq;
create table dw.dim_customer_pk_lookup (
entity_bk varchar not null primary key,
entity_key bigint not null default nextval('dw.dim_customer_seq')
);
drop table if exists dw.dim_customer_main_batch_info;
create table dw.dim_customer_main_batch_info (
entity_key bigint not null primary key,
is_inferred smallint not null default 0,
is_deleted smallint not null default 0,
hash varchar(128),
batch_date timestamp not null,
batch_number bigint not null
);
drop table if exists dw.dim_customer_main;
create table dw.dim_customer_main (
entity_key bigint primary key,
customer_id bigint,
date_created timestamp,
date_updated timestamp,
email_key bigint,
email varchar(255),
first_name varchar(255),
last_name varchar(255),
is_enabled bool,
additional_data json,
shipping_country varchar(255)
);
create index dim_customer_main_email_key_idx
on dw.dim_customer_main using btree
(email_key);
drop table if exists dw.dim_customer_main_history;
create table dw.dim_customer_main_history (
-- History part
is_inferred smallint default 0,
is_deleted smallint not null default 0,
hash varchar(128),
batch_date timestamp,
batch_number bigint,
batch_date_new timestamp,
batch_number_new bigint,
-- Main part
entity_key bigint,
customer_id bigint,
date_created timestamp,
date_updated timestamp,
email_key bigint,
email varchar(255),
first_name varchar(255),
last_name varchar(255),
is_enabled bool,
additional_data json,
shipping_country varchar(255)
);
create index dim_customer_main_history_entity_key_idx
on dw.dim_customer_main_history using btree
(entity_key);
create index dim_customer_main_history_batch_date_idx
on dw.dim_customer_main_history using btree
(batch_date);
create index dim_customer_main_history_batch_date_new_idx
on dw.dim_customer_main_history using btree
(batch_date_new);
create index dim_customer_main_history_email_key_idx
on dw.dim_customer_main_history using btree
(email_key);
Target table Load script:
-- ETL code for loading stage.customer to dw.dim_customer_main
drop table if exists stage.dim_customer_main_batch; -- Won't drop to avoid unnoticed collisions
create table stage.dim_customer_main_batch as
select
current_timestamp as batch_date,
#JOB_ID# as batch_number
;
drop table if exists stage.dim_customer_main_stage1;
create table stage.dim_customer_main_stage1 as
select
customer_id,
date_created,
date_updated,
email,
first_name,
last_name,
is_enabled,
additional_data,
shipping_country,
entity_bk,
email_dim_email_bk,
hash,
row_number() over (partition by entity_bk order by date_updated desc nulls last, hash) as row_number
from (
select
customer_id,
date_created,
date_updated,
email,
first_name,
last_name,
is_enabled,
additional_data,
shipping_country,
version,
coalesce(customer_id || '', '') as entity_bk,
email || '' as email_dim_email_bk,
md5(
coalesce(customer_id || '', '') ||
coalesce(to_char(date_created, 'YYYYMMDDHH24MISS') || '', '') ||
coalesce(email || '', '') ||
coalesce(first_name || '', '') ||
coalesce(last_name || '', '') ||
coalesce(is_enabled || '', '') ||
coalesce(additional_data || '', '') ||
coalesce(shipping_country || '', '')
) as hash
from (
select
customer_id,
date_created,
date_updated,
lower(trim(email)) as email,
first_name,
last_name,
is_enabled,
additional_data,
json_extract_path_text(additional_data, 'attributes', 'shippingCountry') as shipping_country,
version
from stage.customer
) s2
) s1;
create index dim_customer_main_stage1_entity_bk_idx
on stage.dim_customer_main_stage1 using btree
(entity_bk);
create index dim_customer_main_stage1_row_number_idx
on stage.dim_customer_main_stage1 using btree
(row_number);
create index dim_customer_main_stage1_email_dim_email_bk_idx
on stage.dim_customer_main_stage1 using btree
(email_dim_email_bk);
-- Inferred entities loading start
-- Inferred entity: dim_email_main
begin;
lock table dw.dim_email_pk_lookup in exclusive mode;
lock table dw.dim_email_main_batch_info in exclusive mode;
lock table dw.dim_email_main in exclusive mode;
drop table if exists stage.dim_email_main_inferred_#JOB_ID#;
create table stage.dim_email_main_inferred_#JOB_ID# as
select
p.entity_key, -- Not null if entity exists, but was not loaded to this entity suffix before
s1.email_dim_email_bk as entity_bk ,
max(s1.email) as email
from stage.dim_customer_main_stage1 s1
left join dw.dim_email_pk_lookup p
on p.entity_bk = s1.email_dim_email_bk
left join dw.dim_email_main_batch_info bi
on bi.entity_key = p.entity_key
where s1.row_number = 1
and s1.email_dim_email_bk is not null -- Ignoring NULL FKs
and bi.entity_key is null -- Entity either completely new or was not loaded to this entity suffix before
group by 1,2
;
create index dim_email_main_inferred_#JOB_ID#_entity_bk_idx
on stage.dim_email_main_inferred_#JOB_ID# using btree
(entity_bk);
insert into dw.dim_email_pk_lookup (entity_bk)
select i.entity_bk
from stage.dim_email_main_inferred_#JOB_ID# i
where i.entity_key is null -- Entity is completely new
;
-- Analyze takes too much time, disabled for inferred entities
-- analyze dw.dim_email_pk_lookup;
insert into dw.dim_email_main_batch_info (
entity_key,
is_inferred,
is_deleted,
hash,
batch_date,
batch_number
)
select
p.entity_key, -- Using just generated or already exising key which was not loaded to this entity suffix before
1 as is_inferred,
0 as is_deleted,
'dw.dim_customer_main' as hash,
b.batch_date,
b.batch_number
from stage.dim_email_main_inferred_#JOB_ID# i
left join dw.dim_email_pk_lookup p
on p.entity_bk = i.entity_bk
cross join stage.dim_customer_main_batch b
;
-- Analyze takes too much time, disabled for inferred entities
-- analyze dw.dim_email_main_batch_info;
insert into dw.dim_email_main (
entity_key ,
email
)
select
p.entity_key ,
i.email
from stage.dim_email_main_inferred_#JOB_ID# i
join dw.dim_email_pk_lookup p
on p.entity_bk = i.entity_bk
;
-- Analyze takes too much time, disabled for inferred entities
-- analyze dw.dim_email_main;
commit;
-- Inferred entities loading end
-- Generating the list of new/updated/deleted entities
begin;
lock table dw.dim_customer_pk_lookup in exclusive mode;
lock table dw.dim_customer_main_batch_info in exclusive mode;
lock table dw.dim_customer_main in exclusive mode;
drop table if exists stage.dim_customer_main_pk_batch_info_stage;
create table stage.dim_customer_main_pk_batch_info_stage as
select
s1.entity_bk,
p.entity_key, -- Will be null for new entities
bi.is_inferred as is_inferred_old,
0 as is_inferred,
bi.is_deleted as is_deleted_old,
case when s1.entity_bk is null then 1 else 0 end as is_deleted,
bi.hash as hash_old, -- Saving old hash and batch information for updated entities
s1.hash,
bi.batch_date as batch_date_old,
bi.batch_number as batch_number_old,
b.batch_date,
b.batch_number
from stage.dim_customer_main_stage1 s1
left join dw.dim_customer_pk_lookup p
on p.entity_bk = s1.entity_bk
left join dw.dim_customer_main_batch_info bi
on bi.entity_key = p.entity_key
cross join stage.dim_customer_main_batch b
where (s1.entity_bk is not null
and s1.row_number = 1
and ((p.entity_key is null) -- New entity
or (bi.entity_key is null) -- Entity key exists, but not in this entity subname (sattelite)
or (bi.is_inferred = 1) -- This entity subname was loaded, but as inferred
or (bi.is_deleted = 1) -- This entity subname was deleted before, but arrived again now
or (coalesce(bi.hash, '') != s1.hash)) -- This entity subname was loaded, but the attributes changed (or we didn't track history before)
)
or (s1.entity_bk is null -- Entity is missing from loaded full snapshot data (deleted)
and bi.is_deleted = 0 -- Entity is not deleted before
and bi.is_inferred = 0 -- We will not delete inferred records, because they were never actually loaded
)
;
create index dim_customer_main_pk_batch_info_stage_entity_bk_idx
on stage.dim_customer_main_pk_batch_info_stage using btree
(entity_bk);
-- Inserting new entities to PK Lookup, generating keys
insert into dw.dim_customer_pk_lookup (entity_bk)
select ps.entity_bk
from stage.dim_customer_main_pk_batch_info_stage ps
where ps.entity_key is null -- Only new entities
;
analyze dw.dim_customer_pk_lookup;
-- Inserting Batch information and Hash for new entities
insert into dw.dim_customer_main_batch_info (
entity_key,
is_inferred,
is_deleted,
hash,
batch_date,
batch_number
)
select
p.entity_key,
ps.is_inferred,
ps.is_deleted,
ps.hash,
ps.batch_date,
ps.batch_number
from stage.dim_customer_main_pk_batch_info_stage ps
join dw.dim_customer_pk_lookup p
on p.entity_bk = ps.entity_bk
where ps.batch_number_old is null -- This entity subname wasn't loaded before
;
-- Updating Batch information and Hash for changed entities
update dw.dim_customer_main_batch_info
set
is_inferred = ps.is_inferred,
is_deleted = ps.is_deleted,
hash = ps.hash,
batch_date = ps.batch_date,
batch_number = ps.batch_number
from stage.dim_customer_main_pk_batch_info_stage ps
where ps.entity_key = dw.dim_customer_main_batch_info.entity_key
and ps.batch_number_old is not null -- This entity subname was already loaded
;
analyze dw.dim_customer_main_batch_info;
-- Generating Stage2 table, similar to target table by structure
drop table if exists stage.dim_customer_main_stage2;
create table stage.dim_customer_main_stage2 as
select
p.entity_key,
s1.customer_id as customer_id,
s1.date_created as date_created,
s1.date_updated as date_updated,
p_email_dim_email.entity_key as email_key,
s1.email as email,
s1.first_name as first_name,
s1.last_name as last_name,
s1.is_enabled as is_enabled,
s1.additional_data as additional_data,
s1.shipping_country as shipping_country
from stage.dim_customer_main_pk_batch_info_stage as ps -- Only new, inferred or updated entities
join stage.dim_customer_main_stage1 as s1 -- Taking other columns from the source table
on s1.entity_bk = ps.entity_bk
join dw.dim_customer_pk_lookup as p -- Using just generated or already exising keys
on p.entity_bk = ps.entity_bk
left join dw.dim_email_pk_lookup as p_email_dim_email
on p_email_dim_email.entity_bk = s1.email_dim_email_bk
where s1.entity_bk is not null -- Entity not deleted
and s1.row_number = 1
;
-- Inserting updated entities to History
insert into dw.dim_customer_main_history
select
ps.is_inferred_old as is_inferred,
ps.is_deleted_old as is_deleted,
ps.hash_old as hash,
ps.batch_date_old as batch_date,
ps.batch_number_old as batch_number,
ps.batch_date as batch_date_new,
ps.batch_number as batch_number_new,
t.*
from dw.dim_customer_main t
join stage.dim_customer_main_pk_batch_info_stage ps
on ps.entity_key = t.entity_key
where ps.batch_number_old is not null -- This entity suffix already existed
-- Not keeping the history, generated by the same Batch (parent IDs coming in the same Batch as child)
and not (ps.batch_number_old = ps.batch_number and ps.is_inferred_old = 1)
;
analyze dw.dim_customer_main_history;
-- Deleting updated entities from target table
delete from dw.dim_customer_main
where entity_key in ( -- or where exists
select ps.entity_key
from stage.dim_customer_main_pk_batch_info_stage ps
where ps.entity_key is not null
and ps.batch_number_old is not null -- This entity suffix already existed
);
-- Inserting new, inferred and updated entities to the target table
insert into dw.dim_customer_main (
entity_key,
customer_id,
date_created,
date_updated,
email_key,
email,
first_name,
last_name,
is_enabled,
additional_data,
shipping_country
)
select
entity_key,
customer_id,
date_created,
date_updated,
email_key,
email,
first_name,
last_name,
is_enabled,
additional_data,
shipping_country
from stage.dim_customer_main_stage2
;
analyze dw.dim_customer_main;
commit;
- The only thing left to do is to add two scripts to the ETL process: loading the staging table with recent changes, and executing our auto-generated script to load the data into DWH, and set the dependency between them.
Actually, the ETL script we generated doesn’t care whether you load the full table or just the recent changes, it will only update the new or changed records anyway, but it will take more time with full loads (as mentioned above, to track deleted records, you have to do a full load every time).
Since the configuration is stored in a SQLite file, whenever a source table is changed, you only have to add it in the staging table loading script, adapt for this change in the interface (typically, just add a new column) and re-save the generated files. And of course, manually update the structure of the existing tables respectively (for the staging table, main and history DWH tables). You can of course drop and re-create the target tables and reload then again, but then you’ll lose the old changes history.
Adding a new column to the existing tables:
alter table stage.customer add column new_column varchar(255);
alter table dw.dim_customer_main add column new_column varchar(255);
alter table dw.dim_customer_main_history add column new_column varchar(255);
Subscribe via RSS
{kind=link}